> For the complete documentation index, see [llms.txt](https://docs.denvrdata.com/docs/llms.txt). Markdown versions of documentation pages are available by appending `.md` to page URLs; this page is available as [Markdown](https://docs.denvrdata.com/docs/additional-information/faqs/desktop-vs-data-center-gpus.md).
# Desktop vs data center GPUs
The NVIDIA family of data center GPUs (A100/H100/B100) provide significant advantages over all classes of desktop GPUs:
## Tensor Float (TF32) data type
NVIDIA A100 introduces a new hardware data type called 'TF32' which speeds single-precision work, while maintaining accuracy and using no new code. TF32 is a hybrid data type that delivers sufficient precision for tensor operations without the full size of FP32 that slows processing and bloats memory.
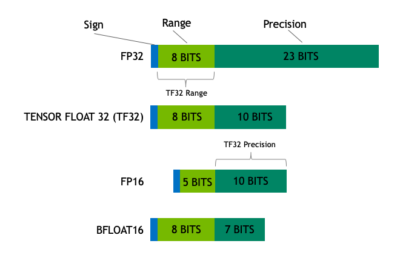
The result is an **8X speed improvement** over FP32 where the reduced precision still matches FP16. This is optimal for matrix math used in Machine Learning.
Read more:
*
## Structural sparsity
Sparsity is an optimization technique that creates a more efficient network from a dense network, and can make better predictions in a limited time budget, react more quickly to unexpected input, or fit into constrained deployment environments.
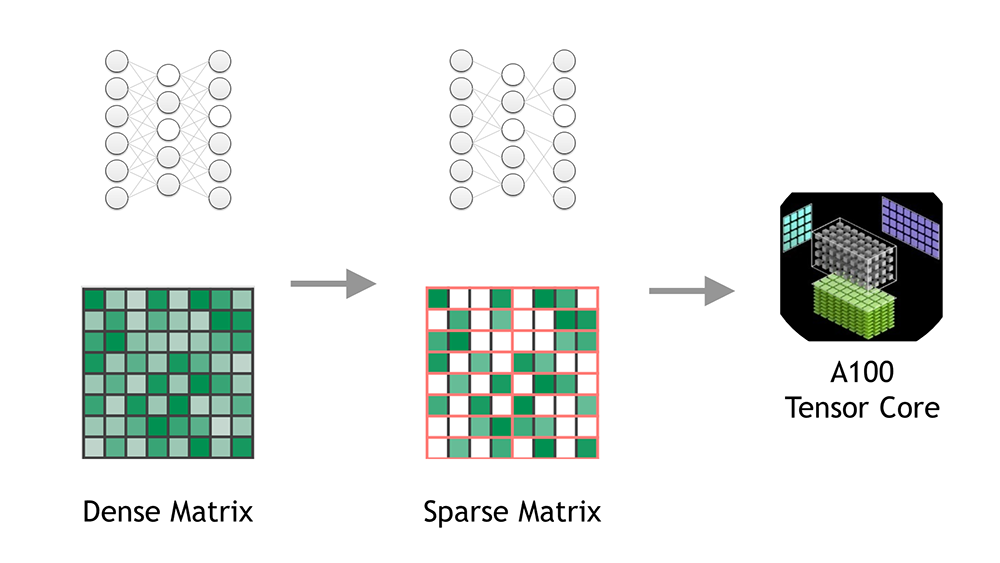
Use of sparsity for inferencing achieves **2X performance improvement** for TF32, FP16, and INT8 operations over non-sparse operations.
Read more:
*
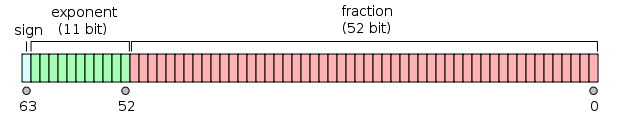
## Double-precision floating (FP64)
IEEE 754 double-precision binary floating-point format provides 16 decimal digits of precision. This is format is used for scientific computations with strong precision requirements.
Most GPUs have severely limited FP64 performance - operating at 1/32 of FP32 performance. The A100 computes FP64 at 1/2 of FP32 which is a dramatic acceleration over CPU, desktop GPUs, and other data center GPUs.
Read more:
*
## NvLink for advanced multi-GPU
HGX A100 systems include NVIDIA Gen4 NvLink (SXM4) which provides 600 GB/s of GPU-to-GPU bandwidth. This is an over 8X improvement over PCIe Gen4 which offers 64 GB/s of bandwidth. The HGX H100 systems use Gen5 NvLink (SXM5) for 900 GB/s.
This architecture is critical for models that require more GPU working memory than is available in a single GPU.
## Multi-Instance GPU (MIG)
MIG partitions NVIDIA GPUs into as many as seven instances, each hardware isolated with its own high-bandwidth memory, cache, and compute cores.\
\
These 'fractional' GPU configurations provide 10GB or 20GB memory options. The benefits of this are:
1. Allocate only GPU resources needed for a workload
2. Test GPU features (per above) without needing to configure a full system
3. Save costs for education and analytics tasks before operating with full GPU and multi-GPU configurations.
Read more:
*
## Compute Fabric
AI Factory deployments include dedicated networks exclusively for the use by GPUs and are capable of scaling from hundreds to thousands of nodes.
Denvr Cloud implements fabrics from 800G to 3200G per node for AI Training using either InfiniBand or RoCE v2 technologies. Multi-node is mandatory for Large Language Models (LLM) training like GPT-3 that are unachievable with Ethernet-based clusters.
Read more:
*
